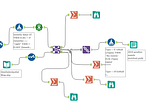
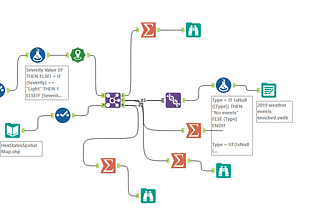
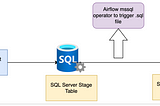
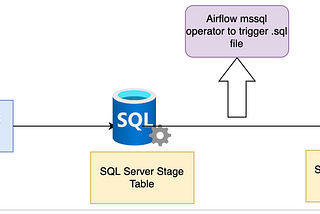
Alteryx to Spark Converter ToolTool link— https://alteryx2spark-jxbkewujwixs7547z4iaru.streamlit.app/Apr 1, 2023Apr 1, 2023
Spark df Upsert (SCD-1 and SCD-2) records to RDBMSThrough Spark code we can find upsert records by comparing source data with the target data (if you want to know about finding the upsert…Oct 12, 2022Oct 12, 2022
SCD Type-1 (Upsert) implementation in Spark ScalaIf source don't have a date column, below is the implementation of attaching a date column with current date for each run.Sep 7, 2022Sep 7, 2022
Important concept in spark -Hash Partitioning, Range Partitioning and Custom PartitioningPartitioning — it means dividing the data into small parts and storing it in distributed systems for parallel computing.Jun 28, 2022Jun 28, 2022
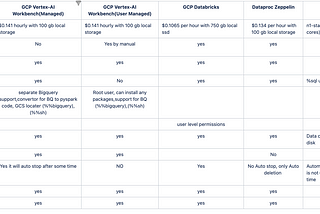
Best Notebook for testing/ spark code on Google cloud clustersI have prepared a poc kind of comparison for the best notebook among jupyter, databricks and zeppelin notebooks on top of dataproc cluster…May 24, 2022May 24, 2022
Easiest way of running spark code in jupyter notebook without heavy installation/configuration1. First you will need to install Docker Desktop. Go to Docker’s website and download Docker Desktop as shown in the screenshot below and…May 9, 2022May 9, 2022
Important interview point on -coalesce() vs repartition() performance evaluationWe may think that coalesce is the best approach for reducing the number of partitions when compare with repartition. Yes, but not in all…Apr 4, 20222Apr 4, 20222